| Сейчас на форуме: Magister Yoda, vasilevradislav (+3 невидимых) |
| eXeL@B —› Крэки, обсуждения —› Компиляция С/С++ с фрагментацией процедур и линковка с фрагментацией obj-файлов — что за ключи? |
| Посл.ответ | Сообщение |
|
|
Создано: 25 февраля 2015 23:12 · Поправил: toxanbi · Личное сообщение · #1 Попытаюсь без лишних деталей обобщённо описать суть ситуацию и предмет вопроса. Вопрос простой, но у меня не получается описывать его в двух предложениях. (Маленькая заметка: если в описании того, как всё происходит, я где-то не прав, ткните меня носом, но прежде чем тыкать, дважды проверьте себя — правы ли вы.) Я анализировал под дизассемблером/отладчиком некие бинарники (не от нечего делать), и наткнулся на определённую деталь в особенностях того, как они скомпилированы/слинкованы, и мне интересно, как эти особенности повторить (воспроизвести). Итак, есть определённый бинарник, написанный на С и С++, про который с очень большой степенью уверенности можно сказать, что для компиляции и линковки использовались Microsoft-овские компилятор (cl.exe) и линкер (link.exe), то есть те же, что шли в составе MSVC++. Поскольку есть отладочные символы, я вижу все имена функций/методов, глобальных переменных и констант, таблиц виртуальных функций и прочих внутренностей, а поскольку значительная часть кода написана на С++ и имена подверглись декорированию, я так же отлично вижу, что часть процедур — это методы классов, вижу к каким классам они принадлежат, их аргументы (их количество и тип). Наблюдения, если кратко (дальше я поясню более детально), заключаются в следующем: 1. Порядок, в котором процедуры размещены в секции кода — он весьма, так скажем, хаотичен. Он выглядит так, как будто все процедуры подверглись переупорядочиванию, то есть порядок, в котором они размещены в секции кода, кардинально отличается от порядка, в котором имплементации процедур размещены в исходниках (кто-то спросит «а почему он должен совпадать?» — см. далее). 2. Обычно процедура в скомпилированном виде выглядит весьма компактно, в том смысле, что, глядя на дизасм-листинг, можно с определённостью сказать, что вот здесь у неё начало (точка входа), а здесь — край, и что инструкции, принадлежащие процедуре, занимают непрерывный диапазон байтов в секции кода (то есть внутри процедуры может быть сколько угодно условных и безусловных джампов, но там посреди «тела» процедуры нет включений какого-нибудь мусора, каких-нибудь данных или какой-нибудь другой процедуры или её куска. В этом случае можно говорить о цельных процедурах. Так вот в моём случае весомая доля процедур (где-то 30 %) — фрагментированы, то есть у таких процедур существуют крохотные кусочки (состоящие из обычно из 2—3 инструкций, хотя есть и большие куски), которые оторваны от основного тела процедуры и отнесены от неё очень далеко. Второй пункт в разрезе «что вынуждает компилятор поступать именно так, как это линкуется и как заставить компилятор поступить с моим кодом так же?» меня волнует больше, чем первый. Теперь поясню пункты. Предполагается, что вы знаете, как осуществляется компиляция (в плане кодогенерации), как генерируются OBJ-файлы (и что у них внутри), как линкер «сшивает» их вместе, какая информация ему доступна и что он может двигать и менять, а что нет. Вернее, знаете, как с этим дела обстоят у MS-овских компилятора и линкера. 1. «А почему порядок того, как функции располагаются в секции кода, должен соответствовать порядку функций в исходном файле?». А потому, что, в общем-то, если не прилагать дополнительных усилий, то именно так и будет, по крайней мере в случае CL. Если вы возьмёте чистый .c-файл и поместите в него, скажем, 4 функции foo_A(), foo_C(), foo_B(), foo_D() и скомпилируете это с помощью CL в obj, а этот obj загоните в дизассемблер (по ходу поста для демонстрации для определённости я буду использовать dumpbin, который идёт в составе MSVC++ / Platform SDK / DDK), то увидите, что в obj-файле эти процедуры идут именно в таком порядке — компилятор не переставил их алфавитном порядке, а честно положил их в obj в том порядке, в каком они шли в исходнике, ничего не выкинув (выкинуть какую-либо процедуру у него не хватит полномочий, потому что на этапе компиляции он не обладает наперёд информацией о том, понадобится ли та или иная функция, когда генерируемый в данный момент obj-файл будет слинковываться с какими-то другими obj-файлами). Можно проверить: Code:
cl /c test.c /Fotest.obj && dumpbin /disasm test.obj Code:
Сущности лежат в COFF-файле в том порядке, в каком были в исходнике. Линкеру, конечно, будет известно о каждой сущности (он сможет удовлетворить зависимости других obj-файлов в них), но всё это представляется одним цельным блоком, который линкер не имеет права разрезать: не может вырезать из него функции, не может их раздвигать и сдвигать и переставлять кусочки местами. Если тут кто-то засомневается и скажет, мол, как же так «не может», а как же он тогда обеспечивает выравнивание начал процедур по границе параграфа, то я скажу, что выравнивание начал процедур и паддинги между ними (нужно, к пример, 5 байт перед началом функции для hot-patchability) — это задача уровня компилятора, а не линкера. Для линкера 4 процедуры из примера выше — это единый кусок, линкер может двигать этот кусок как одно целой, может выравнивать его, но не контент внутри. Выравнивание отдельных процедур выполняет компилятор. Попробуем скомпилировать пример выше с двумя противоположенными наборами ключей: /Og /Os /Oy (оптимизация размера) и /Og /Ot (оптимизация скорости — тут-то компилятор и сделает выравнивания). cl /Og /Os /Oy /c test.c /Fotest.obj && dumpbin /disasm test.obj Code:
cl /Og /Ot /c test.c /Fotest.obj && dumpbin /disasm test.obj Code:
В одном случае получились очень компактные процедуры, а в другом — раздутый код из-за выравнивания во имя быстроты. Итак, убедились: за выравнивание начАл функций отвечает компилятор (руководствуясь ключами), а линкер помещает в выходной файл весь кусок из obj-целиком. То, что это единый кусок, можно также сказать, посмотрев на левую колонку в дампах — смещение инструкции относительно начала «куска». Во всех трёх листингах с началом каждой новой функции отсчёт не сбрасывается, а продолжается и доходит в конце до 2Dh, 18h и 3Fh соответственно). Разумеется, при таком подходе после линковки в итоговом файле могут остаться функции (да и вообще сущности), которые никому не нужны, может появиться куча дубликатов одной и той же функции (если это была inline-функция), и нельзя менять порядок отдельных сущностей. Чтобы решить эту проблему, сделали подход, который называется function-level-linking. В CL он включается опцией /Gy, и если его включить — каждая отдельная функция будет заключена в отдельный COMDAT (надеюсь, вы знаете, что это такое), и на этапе линковки линкер будет оперировать не одним большим блоком, а отдельны Добавлено спустя 2 часа 16 минут ... а отдельными COMDAT-ами, которые он может: (а) Переставлять местами в произвольном порядке, (б) Удалять отдельные функции из выходного файла (в) Сливать вместе одинаковые функции из разных входных obj-файлов (технике COMDAT folding) Перекомпилируем изначальный код с ключом /Gy: cl /Gy /c test.c /Fotest.obj && dumpbin /disasm test.obj Code:
Как минимум, теперь видно, что у каждой функции отсчёт смещения инструкции начинается с нуля относительно начала функции. Каждая функция теперь помещена в отдельный COMDAT, и линкер может распоряжаться с ними по отдельности, убирая, двигая, перегруппировывая. (Я специально не стал использовать ключик /symbols у dumpbin-а, чтобы мой стартовый пост не вырос ещё больше по вертикали, а так этот ключик показал бы эффект /Gy ещё больше). Отсюда три важных следствия: (а) Манипуляции на уровне отдельных функций вообще стали возможны как явление. (б) При линковке итогового файла MS-овским линкером ключ /OPT:REF заставит линкер выкинуть все сущности, на которые вообще никто не ссылается (то есть строится граф зависимостей, базовыми узлами которого являются сущности, указанные в директивах /ENTRY и /EXPORT; всё, что не попадает в этот граф — выкидывается). (в) MS-овский линкер позволяет приказать ему поместить сущности внутри секции в любом произвольном порядке с помощью ключика /ORDER. Если помните, я начал с того, что в первом пункте сказал, что порядок следования функций в секции кода выглядит очень странным, случайным и запутанным, и на фоне того, что в базовом случае порядок следования функций в итоговом файле повторяет порядок следования функций в файлах-исходниках (и порядок следования объектных файлов на входе линкера), крайне маловероятной выглядит версия, что этот запутанный порядок берёт своё начало из исходников. Меняет ли в этой картине что-то тот факт, что у нас есть опции /Gy и /OPT:REF для компилятора и линкера соответственно? Могут ли эти опции кардинально поменять порядок следования процедур в итоговом бинарнике? Проведём эксперимент. Сделаем 3 файла-исходника (alpha.c, beta.c, gamma.c) по 4 функции в каждом (с постфиксами _AAAA, _CCCC, _BBBB, _DDDD), при этом в каждом файле оставим одну функцию неиспользуемой, а линкер заставим экспортировать только одну из них (создадим DLL с одним экспортом без DllEntryPoint). obj-файлы на вход линкеру подадим в таком порядке: beta.obj gamma.obj alpha.obj Порядок файлов выбран преднамеренно таким, чтобы не повторять алфавитный. Кроме того, для каждого .c-файла будут создан .h-файл с прототипами функций, которые будут включены в каждый .c-файл в порядке gamma.h alpha.h beta.h Порядок следования прототипов будет таким: _BBBB, _DDDD, _AAAA, _CCCC. Порядок следований реализаций — таким: _AAAA, _CCCC, _BBBB, _DDDD. На этой картинке показано, какие есть функции, стрелками показано как они вызывают друг друга: 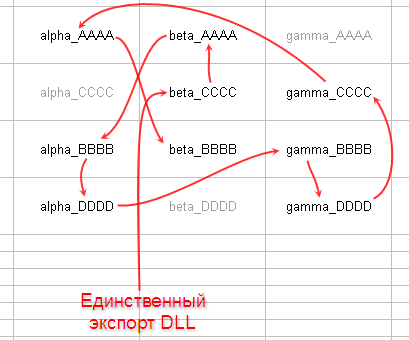 или, при взгляде с другой стороны, кто от кого зависит (кто на кого ссылается). Функции alpha_CCCC, beta_DDDD и gamma_AAAA являются сиротами — от них никто не зависит (никто на них не ссылается). alpha.h: Code:
beta.h Code:
gamma.h: Code:
alpha.c Code:
beta.c: Code:
gamma.c: Code:
На самом деле я решил ещё добавить [omega.c] с никем не используемой пустой функцией omega_dummy() и подавать omega.obj на вход линкеру предпоследним (перед alpha.obj). Добавлено спустя 2 часа 16 минут Теперь скомпилируем и посмотрим, каким будет порядок следования функций в секции кода полученной DLL. Что является определяющим фактором для этого: порядок, в котором идут прототипы, или же порядок, в котором идут реализации, или же алфавитный порядок имён функций, а кроме того, вносит ли вклад порядок перечисления obj-файлов на вход линкера или играет роль алфавитный порядок имён obj-файлов? Сперва скомпилируем без опций /Gy и /OPT:REF и посмотрим на базовый порядок следования функций в секции кода DLL-шки: Code:
Вывод: Code:
Итак, делаем вывод, что в отсутствие ключей /Gy и /OPT:REF порядок следования функций в пределах obj-файлов определяется порядком следования реализаций (а не прототипов, и не алфавитным), а в пределах всего целевого файла-образа (DLL-ки) — порядком подачи obj-файлов на вход линкера (а алфавитным порядком имён obj-файлов). Так как ключей /Gy и /OPT:REF не было, видно, что неиспользуемые функции не убрались из образа. Теперь добавим /Gy, но по прежнему соберём без /OPT:REF — на этот раз линкер может переставлять функции местами, но не может выкидывать их: Code:
Даёт: Code:
Как видно, один только /Gy не меняет картину никак, порядок остаётся тем же, неиспользуемые функции не выкинуты. Ключ /OPT:REF без /Gy даёт ту же картину — линкер не может убрать контент omega.obj, потому что не знает, что там только одна функция, от которой никто не зависит. Теперь, наконец, включим /Gy для компиляции и /OPT:REF у линкера: Code:
Вывод: Code:
Видим, что наконец-то линкер ликвидировал неиспользуемые alpha_CCCC, beta_DDDD, gamma_AAAA и omega_dummy. Но(!!!), вопреки некоторым ожиданиям, помимо исключения неиспользуемых функций, с порядком следования функций ничего не произошло: функции по-прежнему своим порядком следования повторяют порядок следования obj-файлов на входе линкера и порядок следования реализаций в отдельно взятых исходниках. Линкер просто убирает ненужное, но никак не перегруппировывает и не переставляет местами отдельные функции. По крайней мере, можно было бы сделать смелое предположение, что с ключом /opt:ref линкер пойдёт от экспортов: сначала «положит» в секцию кода непосредственно сами экспортируемые функции, потом рекурсивно пойдёт по другим функциям, от которых зависят текущие, и будет класть их, и таким образом порядок следования функций повторил бы порядок обхода графа по красным стрелкам. Но нет: линкер не переставляет функции местами сам, а сохраняет оригинальный порядок. Естественно, используя ключ /ORDER можно заставить линкер переставить функции. Теста ради сделаем порядок с упорядочиванием по постфиксам (_AAAA, .... _DDDD): Code:
даёт: Code:
Итак, ещё раз: если obj-файлы получены с ключом /Gy, линкер может удалять некоторые функции (при наличии ключа /OPT:REF) и переставлять их местами (при наличии ключа /ORDER и файла с явным указанием порядка). Но сам по себе линкер функции местами не переставляет. А теперь я возвращаюсь к тому, откуда начал, к первому пункту: в исследуемых бинарниках функции расположены в таком хаотическом порядке, что я никогда не поверю, что этот порядок соответствует порядку их следования в исходниках. Спросите себя сами: если есть проект с 1000 процедур, и есть класс, у которого 10 методов, и эти 10 методов равномерно рассредоточены по всей секции кода и идут вперемешку с методами других классов и обычными функциями, то вы поверите, что этот хаос берёт начало в исходниках? Вот и я не верю. Кроме этого, не особо верится, что при компиляции бинарников авторы зачем-то написали ORDER-файл, где и прописали этот странный порядок следования. Итак, мы имеем два не очень вяжущихся между собой факта: (а) В исследуемых файлах функции идут в странном хаотическом порядке. (б) Компилятор мог бы поменять порядок процедур в пределах obj-файла, но по умолчанию этого не делает. Линкер (если obj-файлы скомпилированы с /Gy) мог бы поменять порядок следования процедур в пределах всего бинарника, но по умолчанию этого тоже не делает, оставляя всё как есть. Вопрос (часть 1): что могло вынудить компилятор и/или линкер перемешать процедуры в итоговом файле? Я не могу точно предположить, на каком этапе — компиляции или линковки — произошло перемешивание, но попробуйте предложить хоть какую-то правдоподобную гипотезу того, как это могло произойти. На самом деле, первый пункт беспокоит меня меньше всего, потому что в худшем случае странный порядок следования процедур можно списать на то, что авторы действительно были настолько упоротыми, что у них в исходных файлах такой бардак, или на то, что они подготовили order-файл и использовали ключ /ORDER, руководствуясь принципом группировки логически связанных функций вместе, так, чтобы при выполнении кода минимизировать число page-fault-ов, вызванных переходом выполнения на страницу, которая вылетела из working-set-а процесса (для такой тонкой оптимизации ключ /ORDER и создавался). Добавлено спустя 2 часа 17 минут Второй пункт намного более серьёзен, потому что для него я не вижу пока никакого решения. Если в первом пункте речь идёт о том, что бинарник выглядит так, как будто кто-то провёл хирургию, манипулируя отдельными функциями (переставляя их), то во втором пункте речь идёт о том, что помимо этого секция кода выглядит так, как будто кто-то провёл хирургию ещё и на уровне процедур: разрезая их на куски и перемещая (и перемешивая) отдельные фрагменты процедур друг относительно друга. Дело в том, что я наблюдаю приличное количество процедур, у которых маленький кусочек «вырезан» из основного тела и унесён куда-нибудь далеко от самой процедуры. Обычно это функции, внутри которых есть ветвление, причём одна из ветвей оказывается очень маленькой (по количеству действий, в которые ветвь выполнения скомпилируется). Возьмём для примера такой код на С++: Code:
Здесь boo — класс, его методы — виртуальные, соглашение — thiscall. Я не компилировал этот кусочек С++-кода, а написал то, во что он скомпилируется, «от руки». Самое главное, что здесь есть ветка, которая выполняется при истинности выражения x->ready == 0 (ветка return 0; ). Вот именно компилируя её, компилятор генерирует условный джамп далеко-далеко за пределы основного тела функции foo — джамп через десятки (если не сотни) других процедур на одну единственную инструкцию (которая, как правило, зануляет какой-нибудь регистр или делает один mov), а затем идёт jmp опять через кучу других процедур обратно в пределы основного тела процедуры foo. То есть выглядит это вот так: Code:
Таким образом, ради xor eax,eax генерируется джамп чёрти-куда, а потом оттуда осуществляется возврат обычным jmp. Основной вопрос здесь состоит в том, чем руководствуется компилятор, когда генерирует огромное множество таких выносных фрагментиков? Большинство фрагментов мелкие: 1—3 инструкции, но попадаются и большие. Что заставляет делать компилятор именно так? Какие особенности кода? Какая комбинация ключей командной строки? При просмотре бинарника в OllyDbg такие отрезанные выносные фрагменты имеют своё имя (как и рядовые неэкспортируемые функции, видимые благодаря наличию отладочных символов), состоящее из имени функции, к которой относится кусочек, символа подчёркивания и десятеричного числа, в большинстве случаев (но не во всех) соответствующего смещению смещения (именно так) в составе джамп-инструкции, ведущий на крохотный кусочек, относительно начала функции. Т.е. если есть отдельно лежащий кусочек «foo_X», на который ведёт джамп-инструкция, начинающаяся по смещению foo+11d, вместо «X» будет число 13 (foo+11d+2, где 2 — размер опкода в составе джамп-инструкции, например 0F85 для JNZ). Правда я не уверен, что символ подчёркивания с числом не добавляет сама OllyDbg. Помимо того, как вообще заставить компилятор генерировать такой код, меня волнует вопрос: если использовался function-level linking (ключ /Gy), как на уровне COFF были представлены такие огрызки функций? Неужели компилятор С/С++ оборачивал не функции целиком в COMDAT-ы, а снисходил до того, чтобы упаковывать отдельные кусочки функций в отдельные COMDAT-ы? Разве он такое умеет? Наблюдение №0: Обычно короткие огрызки процедур размещаются после (по направлению роста адресов) основных частей процедур, но бывает, что и до. Важное наблюдение №1: порядок следования основных частей процедур обычно не соответствует порядку следования огрызков. То есть если в секции кода есть функции: foo, bar, baaz (лежащие в таком порядке), то огрызки могут лежать так: bar_37, foo_19, baaz_74. Важное наблюдение №2: порядок следования огрызков выглядит намного более логичным, систематизированным и упорядоченным, нежели порядок следования основных частей процедур, к которым эти огрызки относятся. В частности: (а) Для тех из методов CPP-классов, что оказались фрагментированными, всегда сперва идут огрызки public-методов, а затем огрызки private-методов. Основные же части методов лежат как попало. (б) Огрызки лежат компактно, прижато друг к другу, и для огрызков фрагментированных методов классов справедливо, что огрызки сгруппированы по признаку принадлежности к классу. Если, к примеру, составить большую таблицу, куда выписывать все сущности (и сами процедуры (их точки входа), и огрызки) секции кода в порядке их появления в секции (в порядке роста адресов), и каждой строке присвоить номер, и взять для примера один класс, его методы, а из них взять подмножество фрагментированных методов, то вот что получается: Code:
Обратите внимание, что основные куски реализаций методов класса лежат как попало: public- и private- методы перемешаны, логический порядок методов нарушен (вместо MethC лежит MethI, вместо F и G переставлены местами, J и K переставлены местами), кроме того, набор методов одного и того же класса размазан по большой зоне и чередуется с большим количеством никак не относящихся к классу CSomeClass процедур — методов других классов или вообще «плоских» функций. Так, например, между конструктором и MethA лежит 11 левых процедур, MethA, MethB и MethI лежат компактно друг за другом. затем между MethI и MethD лежит 7 левых процедур, потом между MethD и MethE — ещё 6 левых процедур, потом между MethE и MethG — аж 159 левых процедур, затем между 6 левых процедур между MethG и MethF, потом одна процедура (являющайся просто функцией, не членом класса) между MethF и MethH, MethH и MethK лежат вплотную друг к другу, потом опять идёт 64 левых процедуры, за которыми лежит MethJ, потом 2 левых процедуры и, наконец, MethC. Под левыми процедурами, ещё раз, я подразумеваю процедуры, которе никак не относятся к классу CSomeClass, а являются либо методами других классов, либо вообще не методами, а просто функциями. А теперь, если посмотреть на то, как лежат огрызки, то видно, что за исключением огрызка конструктора, огрызки других методов лежат строго друг за другом в правильном порядке, занимают непрерывный диапазон номеров в нашей таблице, и между двумя огрызками не оказывается никаких дырок, занятых чем-либо, не относящимся к классу. И глядя на имена методов, к которым относятся огрызки, я чувствую, что огрызки идут именно в том порядке, в каком методы реализованы в исходнике. Это подтверждается и тем, что сперва идут огрызки public-методов, а затем огрызки private-методов. В общем, вырисовывается следующая картина: (1) В перемешивании и перестановке процедур местами замешан всё-таки линкер, а не компилятор. (2) В фрагментации на уровне процедур замешан компилятор, причём огрызки множества функций одного исходника помещаются в один COMDAT, поэтому линкер не может их распотрошить на куски и равномерно размазать по секции кода, разбавив левыми процедурами, что мы видим на примере вышеприведённого класса, где огрызки методов лежат плотно и упорядоченно. Остаётся вопрос: Что вынуждает компилятор подобным образом фрагментировать процедуры (какой набор ключей, какой режим компиляции?) и что вынуждает линкер перемешивать процедуры столь странным образом (кроме ключа /ORDER и ручного упорядочивания?). Добавлено спустя 2 часа 18 минут _________ Некоторые люди, наверное, захотят поковырять сам бинарник. Я конечно, не могу поделиться своим бинарником, но как я уже сказал, он не уникальный в своём роде в плане наблюдаемых эффектов. Каждый может взять ole32.dll своей системы и поковырять её — в ней я наблюдаю те же трюки (как минимум в той версии ole32, которая актуальна для WinXP) , что и в своём бинарнике, к тому же вряд ли кто-то будет сомневаться, что для компиляции ole32.dll использовали MS-овский компилятор и линкер. (И уж точно никто не скажет, что это результат работы криптора или протектора) 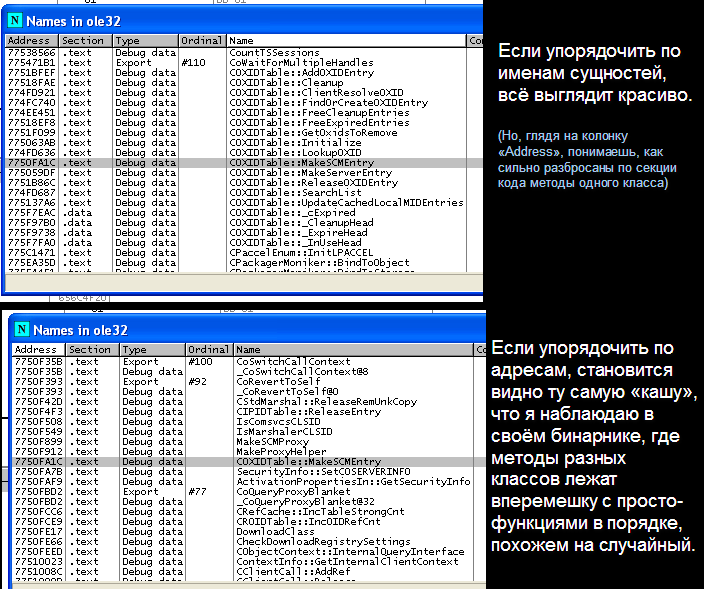 На что я надеюсь: возможно кто-то имел удовольствие компилировать большие проекты, написанные на С/С++, а затем сидеть над ними с отладчиком, и сейчас он вспомнит, что в своём коде замечал аналогичные трюки со стороны компилятора/линкера, и в этом случае можно пойти и посмотреть, что за набор ключей и параметров был скормлен компилятору и линкеру.  |
|
|
Создано: 26 февраля 2015 01:44 · Личное сообщение · #2 СУТЬ ПРОБЛЕМЫ НЕ РАСКРЫТА Я СЧИТАЮ -- НАДО БОЛЬШЕ ПОДРОБНЫХ ГРАФИКОВ, БОЛЬШЕ ДИЗАССЕМБЛЕРНОГО ЛИСТИНГА, БОЛЬШЕ ДАМПОВ ПАМЯТИ!! 
|
|
|
Создано: 26 февраля 2015 01:57 · Поправил: plutos · Личное сообщение · #3 VanHelsing конечно же шутит, а если говорить серьезно, то вам бы сократить размер своего поста раз эдак в десять и постараться сформулировать вопросы в их наиболее общем виде без того, чтобы топить суть дела в массе деталей. Ваш пост подкупает тщательностью и аккуратностью в разработке деталей и больше тянет на статью (в хорошем смысле слова!), но разбираться с такой уймой информации врядли кто-то будет, даже при большом желании. Забавно, что сам пост начинается словами: "Попытаюсь без лишних деталей ..." ----- Give me a HANDLE and I will move the Earth. | Сообщение посчитали полезным: Dynamic, toxanbi |
|
|
Создано: 26 февраля 2015 05:34 · Личное сообщение · #4 тролль и самое главное толку от его вопросов нет, почему, как, зачем, практического смысла в реверсинжиниринге в них нет |
|
|
Создано: 26 февраля 2015 07:08 · Личное сообщение · #5 reversecode пишет: толку от его вопросов нет, почему, как, зачем, практического смысла в реверсинжиниринге в них нет Как знать, мож это поможет понять как IDA бинари получаются разными и уникальными 
----- Get busy living or get busy dying © |
|
|
Создано: 26 февраля 2015 07:14 · Личное сообщение · #6 Краткость - сестра таланта! © А.П. Чехов |
|
|
Создано: 26 февраля 2015 08:30 · Личное сообщение · #7 Getorix это давно не секрет, но в этом опусе я про иду и намёка не увидел |
|
|
Создано: 26 февраля 2015 08:37 · Личное сообщение · #8 toxanbi Ты из академической среди, что-ли? Суть вопросов: как заставить компилятор+линкер побить CFG так, чтобы функции и их части размазало по всему бинарю равномерным слоем? Про функции ты и сам ответил - можно использовать ORDER, а файло со списком генерировать на этапе pre-build step. А вот с частями функций сложнее. Если откусанные части - обработчики ошибок (как exception chunks), то старые компиляторы вполне могли генерировать подобный код для них. А если там сосредоточена нормальная логика, то we need to go deeper. ----- старый пень |
|
|
Создано: 26 февраля 2015 08:46 · Личное сообщение · #9 ToxanBI сразу ясно какая среда не как а почему, у него вопросы из разряда "хочу все знать", почему да почему а практического смысла в этом никакого Добавлено спустя 14 минут Firehacker ? LOL
|
|
|
Создано: 26 февраля 2015 10:10 · Поправил: toxanbi · Личное сообщение · #10 reversecode, >тролль и самое главное толку от его вопросов нет, почему, как, зачем, практического смысла в реверсинжиниринге в них нет Боже мой, вы действительно считаете, что я потратил кучу времени чтобы написать столько текста, ради того, чтобы задать бессмысленный вопрос? Практический смысл вопроса очень большой. Я не хотел об этом писать, чтобы не переводить вопрос в русло «а что такое Х?» и обсуждение самой затеи. Ну так вот, представьте себе, что есть продукт X, исходники которого закрыты; и многие бы не прочь получить исходники X. А теперь вы приходите на суд общественности, и заявляете, что у вас есть исходники X. Поскольку исходники продукта получены не кражей, а реверс-инженирингом, со стороны сообщества очень резонно задать вопрос: а где гарантия, что реверс-инжениринг проведён правильно и предлагаемые исходники — не отсебятина, а действительно соответствуют продукту X? Плохой, сложный и ненадёжный путь доказательства: написать кучу тестов, которые будут проверять, что скомпилированное из отреверсенных исходников работает так же, как и подленник. Но чтобы поверить результатам этих тестов, надо поверить, что сами тесты написаны идеально, то есть проблема остаётся (придётся доказывать безупречность тестов). Есть другой, простой как стальной шарик способ доказать, что исходники 100% соответствуют продукту X: просто скомпилировать эти исходники и сравнить полученный бинарник с оригинальным. Если бинарник, полученный от компиляции исходников, при сравнении окажется байт-к-байту идентичным оригиналу, то может быть лучшим доказательством, что исходники — правильные и действительно соответствуют продукту? Естественно, из сравнения исключаются поля PE-файла, занятые timestamp-ами или паддинги. Естественно, для этого надо компилировать исходники тем же компилятором, что использовался в оригинале, собирать тем же линкером, и с теми же ключами. Поверьте мне, мой скилл глядя на дизассемблерный листинг писать код на С/С++, который при компиляции порождает точно те же инструкции, что я вижу в дизассемблере, точно в таком же порядке, с точно таким же использованием регистров — очень хорош для того, чтобы я вообще брался за эту задачу. Причём это касается не только плоских процедур, но и классов с множественным виртуальным наследованием и прочими штучками С++. И, в общем, я отлично справляюсь и всё получается просто превосходно, за исключением, чёрт возьми, двух факторов: 1. Мне приходится вручную переставлять процедуры местами при линковке, потому что у меня они идут в хорошем порядке, а в оригинале — в чёрт знает каком. 2. Те процедуры, которые в оригинале фрагментированы — в моих руках компилятор генерирует код без этих сумашедших прыжков чёрти-куда через полсекции кода. (Только не надо сейчас тащить сюда свои куски ассемблерных листингов и просить меня быстренько написать для них код на С/С++, чтобы проверить мои способности: у меня нет желания и времени кому-то что-то доказывать, я специально изначально скрыл, зачем мне всё это надо, чтобы избекать спекуляций по этому поводу). Если бы я мог заставить компилятор и линкер в моим руках вести себя точно так же, как они вели себя при компиляции оригинальных бинарников, было бы просто идеально. Потому что если с порядком следования процедур ещё можно сделать какой-то workaround, то с фрагментацией отделных процедур — не так то просто. Да, я прекрасно знаю, что можно сделать очень интеллектуальный диффер двух PE-файлов, который будет для подтверждения эквивалентности двух бинарников строить execution flow graph и сравнивать цепочки инструкций на основе подобчных эффектов их действия, а не тупо сравнивая код побайтно. Но это не так классно, как побайтовое сравнение. В конце-концов, как проще доказать стороннему предвзятому человеку, что твои исходники правильные: сказав ему «возьми и сам сравни побайтово и убедишься», или сказав «смотри, парень, вот мой super sophisticated code differ, натрави на него оригинал и результат компиляции моих исходников, и ты увидишь что мой диффер скажет, что они эквивалентны»? Во втором случае он скажет «ну окей, а где доказательство, что твоя утилита для проверки эквивалентности работает правильно?» и будет прав. (Разумеется, всё это нужно не только и не столько для того, чтобы в конце выполненной работы доказать всем, что код соответствует оригинальному бинарнику, сколько для того, чтобы контролировать самого себя по ходу выполнения реверс-инжениринга, а кроме того, работу по реверс-инженирингу можно сделать распределённой — желающие поучаствовать клонируют себе git-репозиторий, реверсят какую-то функцию, отправляют коммит на сервер, а у сервера репозитория стоит триггер, который берёто новые исходники, собирает из них бинарник и сравнивает полученное с оригиналом, и принимает только те коммиты, которые не ломают побайтовую идентичность). |
|
|
Создано: 26 февраля 2015 10:14 · Личное сообщение · #11 Чувак, извини, но по-моему ты графоман 
|
|
|
Создано: 26 февраля 2015 10:20 · Личное сообщение · #12 toxanbi у тебя асм код перед глазами, смотришь и контролируешь вообще после реверса десятков мегабайт уже все четко и понятно с любым бинарником и такой философией как ты пишешь уже никто не заморачивается TryAga1n второй клерк подрастает, только этот ближе к народу видимо
|
|
|
Создано: 26 февраля 2015 10:47 · Поправил: toxanbi · Личное сообщение · #13 r_e, Нет, я не из академической среды. Но и не стоит думать, что если это мой первый пост на этом форуме, то я за дизассемблер и отладчик взялся пару дней назад. Далеко не пару дней, просто свои проблемы я обычно решаю без посторонней помощи. >Суть вопросов: как заставить компилятор+линкер побить CFG так, чтобы функции и их части размазало по всему бинарю равномерным слоем? Верно, но важен не столько факт размазывания, сколько принуждение компилятора и линкера работать так, как они работали при компиляции оргининала (см. выше), чтобы при компиляции отверсенных исходников получить такой же бинарник. Дело в том, что компиляции — процесс детерминистичный, и если много раз компилировать одни и те же исходники тем же самым компилятором с теми же самыми ключами, результат будет всё время один и тот же. Есть, конечно , но я подобные трюки (перемешанные процедуры и фрагментация) вижу даже в бинарниках бородатых годов (времен VC5), когда MS-овский компилятор PGO не поддерживал. >Про функции ты и сам ответил - можно использовать ORDER, а файло со списком генерировать на этапе pre-build step. Да, действительно, можно ключом ORDER, но я сомневаюсь, что авторы моего бирарника, равно как и авторы того же ole32 так заморачивались и писали файл, предпопределяющий очень необычный порядок следования. Мне представляется, что какой-то ключик линкера или определённая комбинация ключиков заставляет линкер самостоятельно (основываясь на чём-то) так переставлять процедуры внутри секции. Но, как я в начале сказал, пункт 1 меня не так беспокоит. >Если откусанные части - обработчики ошибок (как exception chunks), то старые компиляторы вполне могли генерировать подобный код для них. Нет, дело конечно же не в исключениях, я же не дурак, чтобы про такое спрашивать. Выносные отрезные кусочки этот как правило зануление eax и джамп на эпилог функции. Или зануление, поп и джамп на эпилог. Или зануление и LEAVE. Или просто одна единственная инструкция RETN. Вот несколько кусочков из реального бинарника: Code:
Их там полно, тысячи их. Как видно, одинаковые не слиты, никаким COMDAT-folding'ом не пахнет. >А если там сосредоточена нормальная логика, то we need to go deeper. Как правило это альтернативные эпилоги. Ещё это бывают jump-таблицы для switch-ей, но подобные вещи меня нисколько не удивляют и я их воспроизвожу. Можете найти кучу таких фрагментов в ole32:  Очевидно, MS-овский сишный компилятор запросто сам генерирует их, но только при определённых обстоятельствах (задача — понять, что за обстоятельства). |
|
|
Создано: 26 февраля 2015 10:59 · Личное сообщение · #14 может тебе лучше блог завести? явно же заняться нечем
|
|
|
Создано: 26 февраля 2015 11:04 · Личное сообщение · #15 reversecode, Есть у меня свой блог, и свой ресурс с 15-летней историей существования. Давайте не будем о личностях; и прекратите лить свою желчь и спускать шуточки. Давайте по делу, нет? Вопрос вполне конкретный: встречался ли кто-то и знает ли кто-либо, что за ключи (или их комбинация) заставляет упомянутые инсрументы (cl и link) выдавать результаты, описанные в двух пунктах. Пожалуйста, не надо писать комментарии насчёт того, что вы думаете о моём test-driven reverse-engineering подходе, где каждый коммит тестируется на идентичность результирующего бинарника эталонному. Я уж как-нибудь без вас разберусь с методологией разработки. |
|
|
Создано: 26 февраля 2015 11:08 · Личное сообщение · #16 15 летний опыт? мне вас жаль 
|
|
|
Создано: 26 февраля 2015 11:15 · Личное сообщение · #17 Во-первых, есть profile-guided optimization. Насколько я помню, она и может дать куски функции отдельно, в частности для статистики бранчей и предсказания наиболее вероятной ветви. Во-вторых, никто не мешает генерить и кормить ORDER полностью автоматически, не вижу в этом никакой сложности для любого числа функций. |
|
|
Создано: 26 февраля 2015 11:22 · Поправил: toxanbi · Личное сообщение · #18 >Во-первых, есть profile-guided optimization, которая и может дать куски функции отдельно. В MSVC5? В MSVC6? Я же написал выше: toxanbi пишет: Есть, конечно , но я подобные трюки (перемешанные процедуры и фрагментация) вижу даже в бинарниках бородатых годов (времен VC5), когда MS-овский компилятор PGO не поддерживал. >никто не мешает генерить и кормить ORDER полностью автоматически Не спорю, но есть доля сомнения, что именно такой подход использовали авторы моего бинарника и множества других, где я вижу одну и ту же картину. Я же написал выше, что способ /ORDER-ом известен, но ищется что-то автоматическое, возможно недокументированное (у cl и link много недокументированных ключей, возможно использовался один из таких, и кто-нибудь здесь в курсе об этом ключе). |
|
|
Создано: 26 февраля 2015 11:30 · Личное сообщение · #19 за 15 лет мог бы отреверсить не один бинарник что бы понять что ни один аФФтар не будет заниматься подобной чушью как ORDER все компилируют в релизе банальной дефолтовой оптимизацией которая стоит в студии |
|
|
Создано: 26 февраля 2015 11:36 · Поправил: toxanbi · Личное сообщение · #20 >все компилируют в релизе банальной дефолтовой оптимизацией которая стоит в студии Ога-ога, особенно когда никакой студии не используется и проект собирается makefile-ом. Ну и можете на досуге собрать студией с дефолтными опциями какой-нибудь проект и посмотреть, будет там такой адский перемес, или функции лягут в том же порядке, как и в исходнике. Да и фраза про 15 лет относилась не к опыту реверс-инжениринга, а к возрасту интернет-ресурса, но вам же лишь бы оффтопить, отпуская колкие шуточки. |
|
|
Создано: 26 февраля 2015 11:45 · Личное сообщение · #21 зачем мне проверять то что я и так знаю? конечно в файле все функции будут на перемес более того половину функций заинлайнятся а если собрать этот же проект gcc 3 версии то он выстроит все функции по порядку как они расставлены в соурс файлах а если опять же этот проект собрать gcc 4 версии, то функции будут в перемешку при этом даже никаких заумных опций не надо придумать для компилятора занялся бы реальным делом а не сидел не рассуждал о том как правильно пилить дрова, и почему срезы по разному идут, а то дровосеки с тебя угорают
|
|
|
Создано: 26 февраля 2015 11:51 · Личное сообщение · #22 reversecode пишет: зачем мне проверять то что я и так знаю? конечно в файле все функции будут на перемес Пруф из самого первого поста (там где alpha.c, beta.c, gamma.c) показывает, что ни компилятор, ни линкер не меняют порядок сдедования функций. Напишите, какого же волшебного ключика из «дефолтной конфигурации MSVC-проекта» там не хватает, чтобы функции перемешались? |
|
|
Создано: 26 февраля 2015 16:46 · Личное сообщение · #23 reversecode пишет: TryAga1n второй клерк подрастает, только этот ближе к народу видимо НОВЫЙ ОДЕПТ, БОЛЬШЕ И ДОБАВИТЬ НЕЧЕГО!! |
|
|
Создано: 26 февраля 2015 16:56 · Личное сообщение · #24 toxanbi возьми с гугла хоть один большой кроссплатформенный проект и проверь а с тестами на три пустых функции ничего не поймешь |
|
|
Создано: 26 февраля 2015 17:25 · Поправил: dosprog · Личное сообщение · #25 Времена, когда досовские com-файлы после дизассемблирования собирались в полностью идентичный исходному двоичный файл, прошли. Способ контроля хороший, но приходилось повозиться, чтобы всё получилось. В данном случае, не получится полностью воспроизвести область данных компилятора при трансляции хотя бы потому, что исходные, авторские строки-имена функций в декомпилируемом файле уже недоступны. Не надо ставить перед собой невыполнимые задачи имхо |
|
|
Создано: 26 февраля 2015 18:25 · Личное сообщение · #26 toxanbi Допустим что твой вопрос решается какими-то ключами компилятора + линкера, но что более вероятно подбором правильного компилятора и линкера. Что-то сомневаюсь я что у тебя есть коллекция всех компилей и линкеров. Не факт, кстати, что МС компилит сборки паблик утилитами. По идее у них с перфорса билд сервер должен грабить исходники и собирать все автоматом, но как оно там настроено - хз. И работает ли оно вообще под виндой - большой вопрос. ----- старый пень |
|
|
Создано: 26 февраля 2015 20:37 · Поправил: toxanbi · Личное сообщение · #27 dosprog пишет: В данном случае, не получится полностью воспроизвести область данных компилятора при трансляции хотя бы потому, что исходные, авторские строки-имена функций в декомпилируемом файле уже недоступны. Не уверен, что правильно понял, что подразумевается под «областью данных компилятора»... речь о совокупном наборе всех данных, которыми располагает компилятор (и исходники, и ключи командной строки и все прочие любые параметры, так или иначе влияющие на процесс компиляции0? Утверждение, что авторские строки-имена функций неизвестны, неверное, потому что есть отладочные символы, а значит есть информация об именах, типах возвращаемых значений, аргументах и их типах для функций и членов классов, а равно и для глобальных переменных (располагающихся в секции данных) и констант, попавших в секцию кода (авторы использовали /MERGE:.rdata=.text и объединили секции). r_e пишет: но что более вероятно подбором правильного компилятора и линкера. Для начала я хочу разобраться, какая часть «эффектов» обусловлена компилятором, а какая — линкером. Например, я не думаю, что многое зависит от линкера: если только не существует какого-то приватного линкера, по собственной инициативе переставляющего процедуры, остаётся считать, что перестановка местами либо дело рук компилятора (тогда мне пойдёт любая версия линкера), либо результат применения ключа /ORDER (тогда, опять же, линкер особой версии не нужен). С компилятором интереснее. Сейчас, например, CL из MSVC6 отлично справляется с задачей: при компиляции отреверсенного кода воспроизводятся даже откровенно идиотские пассажи, типа таких Code:
не имеющие никакого смысла и пользы (вроде выравнивания последующего блока инструкций ради производительности), являющиеся очевидно недочётами компилятора. r_e пишет: Что-то сомневаюсь я что у тебя есть коллекция всех компилей и линкеров. Не факт, кстати, что МС компилит сборки паблик утилитами. Я уверен, что MS компилириует внутренности системы тем же тулчейном, каким предлагает пользоваться разработчикам железа для создания драйверов под Windows, то есть тем набором инструментов, что поставляется в DDK, а это принципиально те же инструменты, что идут в составе Platform SDK и VS. То есть задача сводится в худшем случае к нахождению нужного билда инструмента. Уверенность в том, что они следуют постулату «использовать один и тот же компилятор для всего» зиждется на том факте, что есть ряд аспектов, не оговариваемых стандартом (например bitfields memory layout), и чтобы не получить так, что вызывающая и вызываемая функция компилироались компиляторами, имеющими разное представление о том, как одна и та же структура выглядит на уровне байтов и битов, они зареклись использовать один и тот же компилятор. Так что нет, они не комплируют системные DLL с помощью gcc. Хотя я не исключаю, что они могли использовать для компиляции приватные билды своих собственных инструментов, которые никогда не выходили в свет. Я об этом думал, я это в уме держу. Но с другой стороны, это же двойная работа: поддерживать одновременно и публичную и приватную версии компилятора. Мне видится, что скорее они работают так: доводят компилятор до ума, тестируют его до посинения, а после того, как доходят до релиза и уверены в достаточной степени, что компилятор не «гонит пургу», — эта релизная версия уходит и в паблик (VS, Platform SDK) и используется для внутренних нужд. Кроме того, в утёкших исходниках win2k можно найти много интересной информации о том, как организован процесс билда: и makefile-ы, и соответствующие батники, и даже валяющийся посреди исходников набор всех утитлит (cl, ml, lib, rc, nmake, midl), который, очевидно, точно использовался внутри компании, а не предназначался для публики (не положили же их в каталог с исходниками, зная наперёд, что они утекут в паблик). Также можно увидеть, что они не патчат компилятор ради каждой собственной хотелки: так, например, для того, чтобы избавиться от попадания в выходные файлы vftable-ов для абстрактных классов (такие классы имеют vftable, где все ячейки заполненные указателем на _purecall, выводящую то самое грустное сообщение «Pure virtual function call»), они написали на Си маленькую утилитку, которая вырезает из obj-файлов нежелательные сущности, и включили эту утилиту в цепочку компиляции. |
|
|
Создано: 26 февраля 2015 22:46 · Поправил: dosprog · Личное сообщение · #28 Тут reversecode уже посоветовал взять проект с исходниками и понасиловать его, глядишь, и вопросы отпадут. Совет по поводу раздумий о текущих по-разному слезах тоже вполне дельный имхо |
|
|
Создано: 27 февраля 2015 00:05 · Личное сообщение · #29 toxanbi, если у вас есть pdb, то что вам мешает посмотреть в нем ключи командной строки проекта? например в TotalCommander через F3 (Ctrl+F) поищите в pdb строки "Yustdafx.h" или "Optimizing Compiler", а там уже смотрите ключи типа "... -FD -EHs -EHc -RTC1 -MTd -Ycstdafx.h ..." и настраивайте свой декомпиль точно также. Еще подобные вещи сильно зависят от версии и патча студии, версию можно подсмотреть в том же pdb на строках типа "C:\Program Files\Microsoft Visual Studio 9.0", а патч уже экспериментальным путем. |
|
|
Создано: 27 февраля 2015 01:11 · Поправил: toxanbi · Личное сообщение · #30 soft пишет: если у вас есть pdb, то что вам мешает посмотреть в нем ключи командной строки проекта? Увы, но у меня символы в формате DBG, а не PDB. Это же не обязательное правило, что в PDB можно найти командную строку, использованную для компиляции каждого отдельного исходника. Посмотрел pdb-шку для test.dll (пруф-пример из первого поста, где были alpha.c, beta.c, gamma.c) — никаких следов командной строки с ключами компиляции не обнаружил. Просканировал 16 Гб отладочных символов, скачанных с MS-овского Symbol Storage — из 1789 файлов только в одном(!) файле (unidrv.pdb) нашлись следы командной строки. Добавлено спустя 18 минут Хотя вот, изменив немного поисковой паттерн, нашёл ещё один pdb-файл. Но их по прежнему единицы из тысяч. Попробую ещё поиграть с поисковыми шаблонами. Добавлено спустя 1 час 1 минуту soft, Хорошая новость: у меня были символы для трёх разных версий ole32, и в одном из pdb-файлов нашлись следы комадной строки. Плохая новость: это оказалась версия, выдернутая из Win7, а не та, которую я показывал выше на скриншотах (она из XP). И в этой новой семёрочной версии ole32 уже нет такого адского расколбаса с порядком следования процедур, и практически невидно фрагментированных процедур (одну я всё-таки нашёл, но поиск был «на глаз», не автоматизированным). |










| eXeL@B —› Крэки, обсуждения —› Компиляция С/С++ с фрагментацией процедур и линковка с фрагментацией obj-файлов — что за ключи? |
 Для печати
Для печати